#apache spark vs hadoop
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Apache Hadoop is a Java-based framework that uses clusters to store and process large amounts of data in parallel. Being a framework, Hadoop is formed from multiple modules which are supported by a vast ecosystem of technologies. Let’s take a closer look at the Apache Hadoop ecosystem and the components that make it up.
1 note
·
View note
Text

Big Data Battle Alert! Apache Spark vs. Hadoop: Which giant rules your data universe? Spark = Lightning speed (100x faster in-memory processing!) Hadoop = Batch processing king (scalable & cost-effective).Want to dominate your data game? Read more: https://bit.ly/3F2aaNM
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
In today’s data-driven world, careers in tech and analytics are booming. Two of the most sought-after fields that international students often explore are Data Engineering and Data Science. Both these disciplines play critical roles in helping businesses make informed decisions. However, they are not the same, and if you're planning to pursue a course abroad, understanding the difference between the two is crucial to making the right career move.
In this comprehensive guide, we’ll explore:
What is Data Engineering?
What is Data Science?
Key differences between the two fields
Skills and tools required
Job opportunities and career paths
Best countries to study each course
Top universities offering these programs
Which course is better for you?
What is Data Engineering?
Data Engineering is the backbone of the data science ecosystem. It focuses on the design, development, and maintenance of systems that collect, store, and transform data into usable formats. Data engineers build and optimize the architecture (pipelines, databases, and large-scale processing systems) that data scientists use to perform analysis.
Key Responsibilities:
Developing, constructing, testing, and maintaining data architectures
Building data pipelines to streamline data flow
Managing and organizing raw data
Ensuring data quality and integrity
Collaborating with data analysts and scientists
Popular Tools:
Apache Hadoop
Apache Spark
SQL/NoSQL databases (PostgreSQL, MongoDB)
Python, Scala, Java
AWS, Azure, Google Cloud
What is Data Science?
Data Science, on the other hand, is more analytical. It involves extracting insights from data using algorithms, statistical models, and machine learning. Data scientists interpret complex datasets to identify patterns, forecast trends, and support decision-making.
Key Responsibilities:
Analyzing large datasets to extract actionable insights
Using machine learning and predictive modeling
Communicating findings to stakeholders through visualization
A/B testing and hypothesis validation
Data storytelling
Popular Tools:
Python, R
TensorFlow, Keras, PyTorch
Tableau, Power BI
SQL
Jupyter Notebook
Career Paths and Opportunities
Data Engineering Careers:
Data Engineer
Big Data Engineer
Data Architect
ETL Developer
Cloud Data Engineer
Average Salary (US): $100,000–$140,000/year Job Growth: High demand due to an increase in big data applications and cloud platforms.
Data Science Careers:
Data Scientist
Machine Learning Engineer
Data Analyst
AI Specialist
Business Intelligence Analyst
Average Salary (US): $95,000–$135,000/year Job Growth: Strong demand across sectors like healthcare, finance, and e-commerce.
Best Countries to Study These Courses Abroad
1. United States
The US is a leader in tech innovation and offers top-ranked universities for both fields.
Top Universities:
Massachusetts Institute of Technology (MIT)
Stanford University
Carnegie Mellon University
UC Berkeley
Highlights:
Access to Silicon Valley
Industry collaborations
Internship and job opportunities
2. United Kingdom
UK institutions provide flexible and industry-relevant postgraduate programs.
Top Universities:
University of Oxford
Imperial College London
University of Edinburgh
University of Manchester
Highlights:
1-year master’s programs
Strong research culture
Scholarships for international students
3. Germany
Known for engineering excellence and affordability.
Top Universities:
Technical University of Munich (TUM)
RWTH Aachen University
University of Freiburg
Highlights:
Low or no tuition fees
High-quality public education
Opportunities in tech startups and industries
4. Canada
Popular for its friendly immigration policies and growing tech sector.
Top Universities:
University of Toronto
University of British Columbia
McGill University
Highlights:
Co-op programs
Pathway to Permanent Residency
Tech innovation hubs in Toronto and Vancouver
5. Australia
Ideal for students looking for industry-aligned and practical courses.
Top Universities:
University of Melbourne
Australian National University
University of Sydney
Highlights:
Focus on employability
Vibrant student community
Post-study work visa options
6. France
Emerging as a strong tech education destination.
Top Universities:
HEC Paris (Data Science for Business)
École Polytechnique
Grenoble Ecole de Management
Highlights:
English-taught master’s programs
Government-funded scholarships
Growth of AI and data-focused startups
Course Curriculum: What Will You Study?
Data Engineering Courses Abroad Typically Include:
Data Structures and Algorithms
Database Systems
Big Data Analytics
Cloud Computing
Data Warehousing
ETL Pipeline Development
Programming in Python, Java, and Scala
Data Science Courses Abroad Typically Include:
Statistical Analysis
Machine Learning and AI
Data Visualization
Natural Language Processing (NLP)
Predictive Analytics
Deep Learning
Business Intelligence Tools
Which Course Should You Choose?
Choosing between Data Engineering and Data Science depends on your interests, career goals, and skillset.
Go for Data Engineering if:
You enjoy backend systems and architecture
You like coding and building tools
You are comfortable working with databases and cloud systems
You want to work behind the scenes, ensuring data flow and integrity
Go for Data Science if:
You love analyzing data to uncover patterns
You have a strong foundation in statistics and math
You want to work with machine learning and AI
You prefer creating visual stories and communicating insights
Scholarships and Financial Support
Many universities abroad offer scholarships for international students in tech disciplines. Here are a few to consider:
DAAD Scholarships (Germany): Fully-funded programs for STEM students
Commonwealth Scholarships (UK): Tuition and living costs covered
Fulbright Program (USA): Graduate-level funding for international students
Vanier Canada Graduate Scholarships: For master’s and PhD students in Canada
Eiffel Scholarships (France): Offered by the French Ministry for Europe and Foreign Affairs
Final Thoughts: Make a Smart Decision
Both Data Engineering and Data Science are rewarding and in-demand careers. Neither is better or worse��they simply cater to different strengths and interests.
If you're analytical, creative, and enjoy experimenting with models, Data Science is likely your path.
If you're system-oriented, logical, and love building infrastructure, Data Engineering is the way to go.
When considering studying abroad, research the university's curriculum, available electives, internship opportunities, and career support services. Choose a program that aligns with your long-term career aspirations.
By understanding the core differences and assessing your strengths, you can confidently decide which course is the right fit for you.
Need Help Choosing the Right Program Abroad?
At Cliftons Study Abroad, we help students like you choose the best universities and courses based on your interests and future goals. From counselling to application assistance and visa support, we’ve got your journey covered.
Contact us today to start your journey in Data Science or Data Engineering abroad!
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Unlocking Opportunities with a Big Data
In today’s digital age, data is being generated at an unprecedented rate. From social media interactions to online transactions, every activity leaves behind a trail of data. But what good is this data if it isn’t understood or utilized? This is where Big Data comes into play. The ability to analyze, interpret, and use data effectively has become a vital skill in almost every industry. For aspiring tech professionals in Kochi, taking a Big Data course could be the key to an exciting and rewarding career.
What is Big Data?
Big Data refers to extremely large datasets that cannot be managed or processed using traditional data processing tools. These datasets are characterized by the 3 Vs:
Volume: Massive amounts of data
Velocity: Speed at which new data is generated
Variety: Different types of data (structured, unstructured, semi-structured)
Big Data technologies and tools enable organizations to gain valuable insights from this information, helping in better decision-making, trend analysis, and even predictive modeling.
Why Big Data Skills Are in Demand
In a data-driven world, companies are investing heavily in Big Data solutions to stay competitive. From healthcare and finance to retail and entertainment, almost every sector is using Big Data to improve efficiency and customer satisfaction. As a result, skilled professionals who can work with data technologies are in high demand.
According to industry reports, the demand for data analysts, data engineers, and Big Data specialists is projected to grow steadily in the coming years. Having Big Data expertise on your resume can open up roles such as:
Data Analyst
Big Data Engineer
Data Scientist
Business Intelligence Analyst
Machine Learning Engineer
Why Choose Kochi for Big Data Training?
Kochi, often referred to as the tech hub of Kerala, is rapidly growing as a center for IT education and innovation. With a number of software companies, incubators, and tech parks, the city offers an ideal environment for learners and professionals.
Opting for a Big Data course in Kochi allows students to:
Learn from experienced trainers in the field
Get exposure to real-world projects
Access industry-standard tools and resources
Network with professionals and peers
What to Expect in a Big Data Course
A comprehensive Big Data training program will generally cover:
Introduction to Big Data concepts
Hadoop Ecosystem (HDFS, MapReduce, YARN)
Apache Spark
NoSQL Databases (MongoDB, Cassandra)
Data Warehousing and ETL tools
Hands-on projects using real datasets
Integration with machine learning and AI
A good course combines theoretical knowledge with practical experience. The goal is to ensure that students are job-ready and capable of contributing to data-driven projects from day one.
Career Pathways after Big Data Training
Big Data is not just about understanding data; it’s about finding the story behind the numbers. Once trained, you can work in multiple domains including:
Finance: Risk assessment, fraud detection
Healthcare: Predictive diagnosis, patient data analysis
Marketing: Customer behavior analytics
E-commerce: Recommendation systems
The scope is enormous, and with digital transformation on the rise, the need for Big Data professionals will only grow.
Why Zoople Technologies is the Right Choice
When it comes to quality training and industry relevance, Zoople Technologies stands out as one of the best software training institutes in Kerala. With a well-structured Big Data course in Kochi taught by experienced professionals, Zoople ensures that learners not only understand core concepts but also get to apply them in real-world projects.
From beginner-friendly modules to advanced technical tools, Zoople offers a complete learning experience. Personalized mentorship, hands-on training, and placement assistance make it a great choice for anyone serious about a career in Big Data.
0 notes
Text
What Are the Hadoop Skills to Be Learned?
With the constantly changing nature of big data, Hadoop is among the most essential technologies for processing and storing big datasets. With companies in all sectors gathering more structured and unstructured data, those who have skills in Hadoop are highly sought after. So what exactly does it take to master Hadoop? Though Hadoop is an impressive open-source tool, to master it one needs a combination of technical and analytical capabilities. Whether you are a student looking to pursue a career in big data, a data professional looking to upskill, or someone career transitioning, here's a complete guide to the key skills that you need to learn Hadoop. 1. Familiarity with Big Data Concepts Before we jump into Hadoop, it's helpful to understand the basics of big data. Hadoop was designed specifically to address big data issues, so knowing these issues makes you realize why Hadoop operates the way it does. • Volume, Variety, and Velocity (The 3Vs): Know how data nowadays is huge (volume), is from various sources (variety), and is coming at high speed (velocity). • Structured vs Unstructured Data: Understand the distinction and why Hadoop is particularly suited to handle both. • Limitations of Traditional Systems: Know why traditional relational databases are not equipped to handle big data and how Hadoop addresses that need. This ground level knowledge guarantees that you're not simply picking up tools, but realizing their context and significance.
2. Fundamental Programming Skills Hadoop is not plug-and-play. Though there are tools higher up the stack that layer over some of the complexity, a solid understanding of programming is necessary in order to take advantage of Hadoop. • Java: Hadoop was implemented in Java, and much of its fundamental ecosystem (such as MapReduce) is built on Java APIs. Familiarity with Java is a major plus. • Python: Growing among data scientists, Python can be applied to Hadoop with tools such as Pydoop and MRJob. It's particularly useful when paired with Spark, another big data application commonly used in conjunction with Hadoop. • Shell Scripting: Because Hadoop tends to be used on Linux systems, Bash and shell scripting knowledge is useful for automating jobs, transferring data, and watching processes. Being comfortable with at least one of these languages will go a long way in making Hadoop easier to learn. 3. Familiarity with Linux and Command Line Interface (CLI) Most Hadoop deployments run on Linux servers. If you’re not familiar with Linux, you’ll hit roadblocks early on. • Basic Linux Commands: Navigating the file system, editing files with vi or nano, and managing file permissions are crucial. • Hadoop CLI: Hadoop has a collection of command-line utilities of its own. Commands will need to be used in order to copy files from the local filesystem and HDFS (Hadoop Distributed File System), to start and stop processes, and to observe job execution. A solid comfort level with Linux is not negotiable—it's a foundational skill for any Hadoop student.
4. HDFS Knowledge HDFS is short for Hadoop Distributed File System, and it's the heart of Hadoop. It's designed to hold a great deal of information in a reliable manner across a large number of machines. You need: • Familiarity with the HDFS architecture: NameNode, DataNode, and block allocation. • Understanding of how writing and reading data occur in HDFS. • Understanding of data replication, fault tolerance, and scalability. Understanding how HDFS works makes you confident while performing data work in distributed systems.
5. MapReduce Programming Knowledge MapReduce is Hadoop's original data processing engine. Although newer options such as Apache Spark are currently popular for processing, MapReduce remains a topic worth understanding. • How Map and Reduce Work: Learn about the divide-and-conquer technique where data is processed in two phases—map and reduce. • MapReduce Job Writing: Get experience writing MapReduce programs, preferably in Java or Python. • Performance Tuning: Study job chaining, partitioners, combiners, and optimization techniques. Even if you eventually favor Spark or Hive, studying MapReduce provides you with a strong foundation in distributed data processing.
6. Working with Hadoop Ecosystem Tools Hadoop is not one tool—its an ecosystem. Knowing how all the components interact makes your skills that much better. Some of the big tools to become acquainted with: • Apache Pig: A data flow language that simplifies the development of MapReduce jobs. • Apache Sqoop: Imports relational database data to Hadoop and vice versa. • Apache Flume: Collects and transfers big logs of data into HDFS. • Apache Oozie: A workflow scheduler to orchestrate Hadoop jobs. • Apache Zookeeper: Distributes systems. Each of these provides useful functionality and makes Hadoop more useful. 7. Basic Data Analysis and Problem-Solving Skills Learning Hadoop isn't merely technical expertise—it's also problem-solving. • Analytical Thinking: Identify the issue, determine how data can be harnessed to address it, and then determine which Hadoop tools to apply. • Data Cleaning: Understand how to preprocess and clean large datasets before analysis. • Result Interpretation: Understand the output that Hadoop jobs produce. These soft skills are typically what separate a decent Hadoop user from a great one.
8. Learning Cluster Management and Cloud Platforms Although most learn Hadoop locally using pseudo-distributed mode or sandbox VMs, production Hadoop runs on clusters—either on-premises or in the cloud. • Cluster Management Tools: Familiarize yourself with tools such as Apache Ambari and Cloudera Manager. • Cloud Platforms: Learn how Hadoop runs on AWS (through EMR), Google Cloud, or Azure HDInsight. It is crucial to know how to set up, monitor, and debug clusters for production-level deployments. 9. Willingness to Learn and Curiosity Last but not least, you will require curiosity. The Hadoop ecosystem is large and dynamic. New tools, enhancements, and applications are developed regularly. • Monitor big data communities and forums. • Participate in open-source projects or contributions. • Keep abreast of tutorials and documentation. Your attitude and willingness to play around will largely be the distinguishing factor in terms of how well and quickly you learn Hadoop. Conclusion Hadoop opens the door to the world of big data. Learning it, although intimidating initially, can be made easy when you break it down into sets of skills—such as programming, Linux, HDFS, SQL, and problem-solving. While acquiring these skills, not only will you learn Hadoop, but also the confidence in creating scalable and intelligent data solutions. Whether you're creating data pipelines, log analysis, or designing large-scale systems, learning Hadoop gives you access to a whole universe of possibilities in the current data-driven age. Arm yourself with these key skills and begin your Hadoop journey today.
Website: https://www.icertglobal.com/course/bigdata-and-hadoop-certification-training/Classroom/60/3044
0 notes
Text
Azure vs. AWS: A Detailed Comparison
Cloud computing has become the backbone of modern IT infrastructure, offering businesses scalability, security, and flexibility. Among the top cloud service providers, Microsoft Azure and Amazon Web Services (AWS) dominate the market, each bringing unique strengths. While AWS has held the position as a cloud pioneer, Azure has been gaining traction, especially among enterprises with existing Microsoft ecosystems. This article provides an in-depth comparison of Azure vs. AWS, covering aspects like database services, architecture, and data engineering capabilities to help businesses make an informed decision.
1. Market Presence and Adoption
AWS, launched in 2006, was the first major cloud provider and remains the market leader. It boasts a massive customer base, including startups, enterprises, and government organizations. Azure, introduced by Microsoft in 2010, has seen rapid growth, especially among enterprises leveraging Microsoft's ecosystem. Many companies using Microsoft products like Windows Server, SQL Server, and Office 365 find Azure a natural choice.
2. Cloud Architecture: Comparing Azure and AWS
Cloud architecture defines how cloud services integrate and support workloads. Both AWS and Azure provide robust cloud architectures but with different approaches.
AWS Cloud Architecture
AWS follows a modular approach, allowing users to pick and choose services based on their needs. It offers:
Amazon EC2 for scalable compute resources
Amazon VPC for network security and isolation
Amazon S3 for highly scalable object storage
AWS Lambda for serverless computing
Azure Cloud Architecture
Azure's architecture is designed to integrate seamlessly with Microsoft tools and services. It includes:
Azure Virtual Machines (VMs) for compute workloads
Azure Virtual Network (VNet) for networking and security
Azure Blob Storage for scalable object storage
Azure Functions for serverless computing
In terms of architecture, AWS provides more flexibility, while Azure ensures deep integration with enterprise IT environments.
3. Database Services: Azure SQL vs. AWS RDS
Database management is crucial for any cloud strategy. Both AWS and Azure offer extensive database solutions, but they cater to different needs.
AWS Database Services
AWS provides a wide range of managed database services, including:
Amazon RDS (Relational Database Service) – Supports MySQL, PostgreSQL, SQL Server, MariaDB, and Oracle.
Amazon Aurora – High-performance relational database compatible with MySQL and PostgreSQL.
Amazon DynamoDB – NoSQL database for low-latency applications.
Amazon Redshift – Data warehousing for big data analytics.
Azure Database Services
Azure offers strong database services, especially for Microsoft-centric workloads:
Azure SQL Database – Fully managed SQL database optimized for Microsoft applications.
Cosmos DB – Globally distributed, multi-model NoSQL database.
Azure Synapse Analytics – Enterprise-scale data warehousing.
Azure Database for PostgreSQL/MySQL/MariaDB – Open-source relational databases with managed services.
AWS provides a more mature and diverse database portfolio, while Azure stands out in SQL-based workloads and seamless Microsoft integration.
4. Data Engineering and Analytics: Which Cloud is Better?
Data engineering is a critical function that ensures efficient data processing, transformation, and storage. Both AWS and Azure offer data engineering tools, but their capabilities differ.
AWS Data Engineering Tools
AWS Glue – Serverless data integration service for ETL workloads.
Amazon Kinesis – Real-time data streaming.
AWS Data Pipeline – Orchestration of data workflows.
Amazon EMR (Elastic MapReduce) – Managed Hadoop, Spark, and Presto.
Azure Data Engineering Tools
Azure Data Factory – Cloud-based ETL and data integration.
Azure Stream Analytics – Real-time event processing.
Azure Databricks – Managed Apache Spark for big data processing.
Azure HDInsight – Fully managed Hadoop and Spark services.
Azure has an edge in data engineering for enterprises leveraging AI and machine learning via Azure Machine Learning and Databricks. AWS, however, excels in scalable and mature big data tools.
5. Pricing Models and Cost Efficiency
Cloud pricing is a major factor when selecting a provider. Both AWS and Azure offer pay-as-you-go pricing, reserved instances, and cost optimization tools.
AWS Pricing: Charges are based on compute, storage, data transfer, and additional services. AWS also offers AWS Savings Plans for cost reductions.
Azure Pricing: Azure provides cost-effective solutions for Microsoft-centric businesses. Azure Hybrid Benefit allows companies to use existing Windows Server and SQL Server licenses to save costs.
AWS generally provides more pricing transparency, while Azure offers better pricing for Microsoft users.
6. Security and Compliance
Security is a top priority in cloud computing, and both AWS and Azure provide strong security measures.
AWS Security: Uses AWS IAM (Identity and Access Management), AWS Shield (DDoS protection), and AWS Key Management Service.
Azure Security: Provides Azure Active Directory (AAD), Azure Security Center, and built-in compliance features for enterprises.
Both platforms meet industry standards like GDPR, HIPAA, and ISO 27001, making them secure choices for businesses.
7. Hybrid Cloud Capabilities
Enterprises increasingly prefer hybrid cloud strategies. Here, Azure has a significant advantage due to its Azure Arc and Azure Stack technologies that extend cloud services to on-premises environments.
AWS offers AWS Outposts, but it is not as deeply integrated as Azure’s hybrid solutions.
8. Which Cloud Should You Choose?
Choose AWS if:
You need a diverse range of cloud services.
You require highly scalable and mature cloud solutions.
Your business prioritizes flexibility and a global cloud footprint.
Choose Azure if:
Your business relies heavily on Microsoft products.
You need strong hybrid cloud capabilities.
Your focus is on SQL-based workloads and enterprise data engineering.
Conclusion
Both AWS and Azure are powerful cloud providers with unique strengths. AWS remains the leader in cloud services, flexibility, and scalability, while Azure is the go-to choice for enterprises using Microsoft’s ecosystem.
Ultimately, the right choice depends on your organization’s needs in terms of database management, cloud architecture, data engineering, and overall IT strategy. Companies looking for a seamless Microsoft integration should opt for Azure, while businesses seeking a highly scalable and service-rich cloud should consider AWS.
Regardless of your choice, both platforms provide the foundation for a strong, scalable, and secure cloud infrastructure in today’s data-driven world.
0 notes
Text
Hadoop vs. Spark: Which Big Data Framework is Right for You?

Introduction
The role of Big Data frameworks in processing large-scale datasets.
Brief introduction to Apache Hadoop and Apache Spark.
Key factors to consider when choosing between the two.
1. Overview of Hadoop and Spark
1.1 What is Hadoop?
Open-source framework for distributed storage and processing.
Uses HDFS (Hadoop Distributed File System) for storage.
Batch processing via MapReduce.
Key components:
HDFS (Storage)
YARN (Resource Management)
MapReduce (Processing Engine)
1.2 What is Spark?
Fast, in-memory data processing engine.
Supports batch, streaming, and real-time analytics.
Provides resilient distributed datasets (RDDs) for fault tolerance.
Key components:
Spark Core (Foundation)
Spark SQL (SQL Queries)
Spark Streaming (Real-time Data)
MLlib (Machine Learning)
GraphX (Graph Processing)
2. Key Differences Between Hadoop and Spark
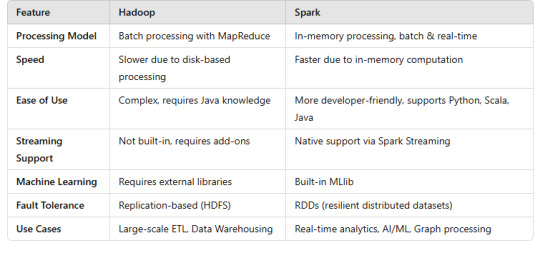
Batch processing of massive datasets.
Data warehousing and ETL pipelines.
Cost-effective storage for structured and unstructured data.
4. When to Use Spark?
Real-time data processing and analytics.
Machine learning and AI workloads.
Graph processing and interactive queries.
5. Hadoop + Spark: The Best of Both Worlds?
Many organizations use Spark on top of Hadoop for faster processing.
HDFS for storage + Spark for computation = Scalable & efficient.
Conclusion
Choose Hadoop for cost-effective batch processing and large-scale storage.
Choose Spark for real-time analytics and AI/ML applications.
Hybrid Approach: Use Hadoop + Spark together for optimal performance.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Big Data vs. EDW: Can Modern Analytics Replace Traditional Data Warehousing?
As organizations increasingly rely on data to drive business decisions, a common question arises: Can Big Data replace an EDW (Enterprise Data Warehouse)? While both play crucial roles in managing data, their purposes, architectures, and strengths differ. Understanding these differences can help businesses decide whether Big Data technologies can entirely replace an EDW or if a hybrid approach is more suitable.

What Does EDW Stand for in Data?
An EDW or Enterprise Data Warehouse is a centralized repository where organizations store structured data from various sources. It supports reporting, analysis, and decision-making by providing a consistent and unified view of an organization’s data.
Big Data vs. EDW: Key Differences
One of the primary differences between Big Data and enterprise data warehousing lies in their architecture and the types of data they handle:
Data Type: EDWs typically manage structured data—information stored in a defined schema, such as relational databases. In contrast, Big Data platforms handle both structured and unstructured data (like text, images, and social media data), offering more flexibility.
Scalability: EDWs are traditionally more rigid and harder to scale compared to Big Data technologies like Hadoop and Spark, which can handle massive volumes of data across distributed systems.
Speed and Performance: EDWs are optimized for complex queries but may struggle with the vast amounts of data Big Data systems can process quickly. Big Data’s parallel processing capabilities make it ideal for analyzing large, diverse data sets in real time.
Big Data Warehouse Architecture
The Big Data warehouse architecture uses a distributed framework, allowing for the ingestion, storage, and processing of vast amounts of data. It typically consists of:
Data Ingestion Layer: Collects and streams data from various sources, structured or unstructured.
Storage Layer: Data is stored in distributed systems, such as Hadoop Distributed File System (HDFS) or cloud storage, allowing scalability and fault tolerance.
Processing Layer: Tools like Apache Hive and Apache Spark process and analyze data in parallel across multiple nodes, making it highly efficient for large data sets.
Visualization and Reporting: Once processed, data is visualized using BI tools like Tableau, enabling real-time insights.
This architecture enables businesses to harness diverse data streams for analytics, making Big Data an attractive alternative to traditional EDW systems for specific use cases.
Can Big Data Replace an EDW?
In many ways, Big Data can complement or augment an EDW, but it may not entirely replace it for all organizations. EDWs excel in environments where structured data consistency is crucial, such as financial reporting or regulatory compliance. Big Data, on the other hand, shines in scenarios where the variety and volume of data are critical, such as customer sentiment analysis or IoT data processing.
Some organizations adopt a hybrid model, where an EDW handles structured data for critical reporting, while a Big Data platform processes unstructured and semi-structured data for advanced analytics. For example, Netflix uses both—an EDW for business reporting and a Big Data platform for recommendation engines and content analysis.
Data-Driven Decision Making with Hybrid Models
A hybrid approach allows organizations to balance the strengths of both systems. For instance, Coca-Cola leverages Big Data to analyze consumer preferences, while its EDW handles operational reporting. This blend ensures that the company can respond quickly to market trends while maintaining a consistent view of critical business metrics.
Most Popular Questions and Answers
Questions: Can Big Data and EDW coexist?
Answers: Yes, many organizations adopt a hybrid model where EDW manages structured data for reporting, and Big Data platforms handle unstructured data for analytics.
Questions: What are the benefits of using Big Data over EDW?
Answers: Big Data platforms offer better scalability, flexibility in handling various data types, and faster processing for large volumes of information.
Questions: Is EDW still relevant in modern data architecture?
Answers: Yes, EDWs are still essential for organizations that need consistent, reliable reporting on structured data. However, many companies also integrate Big Data for advanced analytics.
Questions: Which industries benefit most from Big Data platforms?
Answers: Industries like retail, healthcare, and entertainment benefit from Big Data’s ability to process large volumes of unstructured data, providing insights that drive customer engagement and innovation.
Questions: Can Big Data handle structured data?
Answers: Yes, Big Data platforms can process structured data, but their true strength lies in handling unstructured and semi-structured data alongside structured data.
Conclusion
While Big Data offers impressive capabilities in handling massive, diverse data sets, it cannot completely replace the functionality of an Enterprise Data Warehouse for all organizations. Instead, companies should evaluate their specific needs and consider hybrid architectures that leverage the strengths of both systems. With the right strategy, businesses can harness both EDWs and Big Data to make smarter, faster decisions and stay ahead in the digital age.
Browse Related Blogs –
From Data to Intelligence: How Knowledge Graphs are Shaping the Future
AI to the Rescue: Revolutionizing Product Images in the E-Commerce Industry
0 notes
Text
What is big Data Science?
Big Data Science is a specialized branch of data science that focuses on handling, processing, analyzing, and deriving insights from massive and complex datasets that are too large for traditional data processing tools. The field leverages advanced technologies, algorithms, and methodologies to manage and interpret these vast amounts of data, often referred to as "big data." Here’s an overview of what Big Data Science encompasses:
Key Components of Big Data Science
Volume: Handling massive amounts of data generated from various sources such as social media, sensors, transactions, and more.
Velocity: Processing data at high speeds, as the data is generated in real-time or near real-time.
Variety: Managing diverse types of data, including structured, semi-structured, and unstructured data (e.g., text, images, videos, logs).
Veracity: Ensuring the quality and accuracy of the data, dealing with uncertainties and inconsistencies in the data.
Value: Extracting valuable insights and actionable information from the data.
Core Technologies in Big Data Science
Distributed Computing: Using frameworks like Apache Hadoop and Apache Spark to process data across multiple machines.
NoSQL Databases: Employing databases such as MongoDB, Cassandra, and HBase for handling unstructured and semi-structured data.
Data Storage: Utilizing distributed file systems like Hadoop Distributed File System (HDFS) and cloud storage solutions (AWS S3, Google Cloud Storage).
Data Ingestion: Collecting and importing data from various sources using tools like Apache Kafka, Apache Flume, and Apache Nifi.
Data Processing: Transforming and analyzing data using batch processing (Hadoop MapReduce) and stream processing (Apache Spark Streaming, Apache Flink).
Key Skills for Big Data Science
Programming: Proficiency in languages like Python, Java, Scala, and R.
Data Wrangling: Techniques for cleaning, transforming, and preparing data for analysis.
Machine Learning and AI: Applying algorithms and models to large datasets for predictive and prescriptive analytics.
Data Visualization: Creating visual representations of data using tools like Tableau, Power BI, and D3.js.
Domain Knowledge: Understanding the specific industry or field to contextualize data insights.
Applications of Big Data Science
Business Intelligence: Enhancing decision-making with insights from large datasets.
Predictive Analytics: Forecasting future trends and behaviors using historical data.
Personalization: Tailoring recommendations and services to individual preferences.
Fraud Detection: Identifying fraudulent activities by analyzing transaction patterns.
Healthcare: Improving patient outcomes and operational efficiency through data analysis.
IoT Analytics: Analyzing data from Internet of Things (IoT) devices to optimize operations.
Example Syllabus for Big Data Science
Introduction to Big Data
Overview of Big Data and its significance
Big Data vs. traditional data analysis
Big Data Technologies and Tools
Hadoop Ecosystem (HDFS, MapReduce, Hive, Pig)
Apache Spark
NoSQL Databases (MongoDB, Cassandra)
Data Ingestion and Processing
Data ingestion techniques (Kafka, Flume, Nifi)
Batch and stream processing
Data Storage Solutions
Distributed file systems
Cloud storage options
Big Data Analytics
Machine learning on large datasets
Real-time analytics
Data Visualization and Interpretation
Visualizing large datasets
Tools for big data visualization
Big Data Project
End-to-end project involving data collection, storage, processing, analysis, and visualization
Ethics and Privacy in Big Data
Ensuring data privacy and security
Ethical considerations in big data analysis
Big Data Science is essential for organizations looking to harness the power of large datasets to drive innovation, efficiency, and competitive advantage
0 notes
Text
Data Engineering Interview Questions and Answers
Summary: Master Data Engineering interview questions & answers. Explore key responsibilities, common topics (Big Data's 4 Vs!), and in-depth explanations. Get interview ready with bonus tips to land your dream Data Engineering job!

Introduction
The ever-growing volume of data presents exciting opportunities for data engineers. As the architects of data pipelines and custodians of information flow, data engineers are in high demand.
Landing your dream Data Engineering role requires not only technical proficiency but also a clear understanding of the specific challenges and responsibilities involved. This blog equips you with the essential Data Engineering interview questions and answers, helping you showcase your expertise and secure that coveted position.
Understanding the Role of a Data Engineer
Data engineers bridge the gap between raw data and actionable insights. They design, build, and maintain data pipelines that ingest, transform, store, and analyse data. Here are some key responsibilities of a data engineer:
Data Acquisition: Extracting data from various sources like databases, APIs, and log files.
Data Transformation: Cleaning, organizing, and transforming raw data into a usable format for analysis.
Data Warehousing and Storage: Designing and managing data storage solutions like data warehouses and data lakes.
Data Pipelines: Building and maintaining automated processes that move data between systems.
Data Security and Governance: Ensuring data security, access control, and compliance with regulations.
Collaboration: Working closely with data analysts, data scientists, and other stakeholders.
Common Data Engineering Interview Questions
Now that you understand the core responsibilities, let's delve into the most frequently asked Data Engineering interview questions:
What Is the Difference Between A Data Engineer And A Data Scientist?
While both work with data, their roles differ. Data engineers focus on building and maintaining data infrastructure, while data scientists use the prepared data for analysis and building models.
Explain The Concept of Data Warehousing And Data Lakes.
Data warehouses store structured data optimized for querying and reporting. Data lakes store both structured and unstructured data in a raw format, allowing for future exploration.
Can You Describe the ELT (Extract, Load, Transform) And ETL (Extract, Transform, Load) Processes?
Both ELT and ETL are data processing techniques used to move data from various sources to a target system for analysis. While they achieve the same goal, the key difference lies in the order of operations:
ELT (Extract, Load, Transform):
Extract: Data is extracted from its original source (databases, log files, etc.).
Load: The raw data is loaded directly into a data lake, a large storage repository for raw data in various formats.
Transform: Data is transformed and cleaned within the data lake as needed for specific analysis or queries.
ETL (Extract, Transform, Load):
Extract: Similar to ELT, data is extracted from its source.
Transform: The extracted data is cleansed, transformed, and organized into a specific format suitable for analysis before loading.
Load: The transformed data is then loaded into the target system, typically a data warehouse optimized for querying and reporting.
What Are Some Common Data Engineering Tools and Technologies?
Data Engineers wield a powerful toolkit to build and manage data pipelines. Here are some essentials:
Programming Languages: Python (scripting, data manipulation), SQL (database querying).
Big Data Frameworks: Apache Hadoop (distributed storage & processing), Apache Spark (in-memory processing for speed).
Data Streaming: Apache Kafka (real-time data pipelines).
Cloud Platforms: AWS, GCP, Azure (offer data storage, processing, and analytics services).
Data Warehousing: Tools for designing and managing data warehouses (e.g., Redshift, Snowflake).
Explain How You Would Handle a Situation Where A Data Pipeline Fails?
Data pipeline failures are inevitable, but a calm and structured approach can minimize downtime. Here's the key:
Detect & Investigate: Utilize monitoring tools and logs to pinpoint the failure stage and root cause (data issue, code bug, etc.).
Fix & Recover: Implement a solution (data cleaning, code fix, etc.), potentially recover lost data if needed, and thoroughly test the fix.
Communicate & Learn: Keep stakeholders informed and document the incident, including the cause, solution, and lessons learned to prevent future occurrences.
Bonus Tips: Automate retries for specific failures, use version control for code, and integrate data quality checks to prevent issues before they arise.
By following these steps, you can efficiently troubleshoot data pipeline failures and ensure the smooth flow of data for your critical analysis needs.
Detailed Answers and Explanations
Here are some in-depth responses to common Data Engineering interview questions:
Explain The Four Vs of Big Data (Volume, Velocity, Variety, And Veracity).
Volume: The massive amount of data generated today.
Velocity: The speed at which data is created and needs to be processed.
Variety: The diverse types of data, including structured, semi-structured, and unstructured.
Veracity: The accuracy and trustworthiness of the data.
Describe Your Experience with Designing and Developing Data Pipelines.
Explain the specific tools and technologies you've used, the stages involved in your data pipelines (e.g., data ingestion, transformation, storage), and the challenges you faced while designing and implementing them.
How Do You Handle Data Security and Privacy Concerns Within a Data Engineering Project?
Discuss security measures like access control, data encryption, and anonymization techniques you've implemented. Highlight your understanding of relevant data privacy regulations like GDPR (General Data Protection Regulation).
What Are Some Strategies for Optimising Data Pipelines for Performance?
Explain techniques like data partitioning, caching, and using efficient data structures to improve the speed and efficiency of your data pipelines.
Can You Walk us Through a Specific Data Engineering Project You've Worked On?
This is your opportunity to showcase your problem-solving skills and technical expertise. Describe the project goals, the challenges you encountered, the technologies used, and the impact of your work.
Tips for Acing Your Data Engineering Interview
Acing the Data Engineering interview goes beyond technical skills. Here, we unveil powerful tips to boost your confidence, showcase your passion, and leave a lasting impression on recruiters, ensuring you land your dream Data Engineering role!
Practice your answers: Prepare for common questions and rehearse your responses to ensure clarity and conciseness.
Highlight your projects: Showcase your technical skills by discussing real-world Data Engineering projects you've undertaken.
Demonstrate your problem-solving skills: Be prepared to walk through a Data Engineering problem and discuss potential solutions.
Ask insightful questions: Show your genuine interest in the role and the company by asking thoughtful questions about the team, projects, and Data Engineering challenges they face.
Be confident and enthusiastic: Project your passion for Data Engineering and your eagerness to learn and contribute.
Dress professionally: Make a positive first impression with appropriate attire that reflects the company culture.
Follow up: Send a thank-you email to the interviewer(s) reiterating your interest in the position.
Conclusion
Data Engineering is a dynamic and rewarding field. By understanding the role, preparing for common interview questions, and showcasing your skills and passion, you'll be well on your way to landing your dream Data Engineering job.
Remember, the journey to becoming a successful data engineer is a continuous learning process. Embrace challenges, stay updated with the latest technologies, and keep pushing the boundaries of what's possible with data.
#Data Engineering Interview Questions and Answers#data engineering interview#data engineering#engineering#data science#data modeling#data engineer#data engineering career#data engineer interview questions#how to become a data engineer#data engineer jobs
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
Business Intelligence VS. Data Analytics

Business Intelligence (BI) and Data Analytics are interconnected fields that serve distinct yet complementary roles in leveraging data to enhance decision-making and organizational performance. Here's a technical comparison of the two:
Business Intelligence (BI):
Definition and Scope:
BI encompasses a wide array of processes, technologies, and tools that collect, integrate, analyze, and present business data. It aims to provide historical, current, and predictive views of business operations.
Focus:
The primary focus is on reporting, dashboards, and data visualization to support strategic and tactical decision-making. BI systems typically aggregate data from various sources into a centralized data warehouse.
Techniques:
Techniques used in BI include data mining, querying, online analytical processing (OLAP), and reporting. BI tools often incorporate predefined models and queries for regular reporting.
Tools:
Common BI tools include Microsoft Power BI, Tableau, QlikView, and SAP BusinessObjects. These tools provide robust visualization capabilities and user-friendly interfaces for non-technical users.
Outcome:
The outcome of BI is to provide actionable insights, enhance business processes, and facilitate performance monitoring through KPIs and metrics.
Implementation:
BI implementation often involves the integration of data from various sources, ETL (extract, transform, load) processes, and the creation of data models and dashboards.
Data Analytics:
Definition and Scope:
Data Analytics involves a more technical and detailed examination of raw data to discover patterns, correlations, and trends. It includes descriptive, diagnostic, predictive, and prescriptive analytics.
Focus:
The focus is on deeper data analysis using statistical methods and machine learning techniques to derive insights that can inform specific business questions or problems.
Techniques:
Techniques used in data analytics include statistical analysis, predictive modeling, machine learning algorithms, data mining, and text analytics. It involves exploring and interpreting large datasets.
Tools:
Common data analytics tools include Python, R, SAS, Apache Spark, and Hadoop. These tools provide extensive libraries and frameworks for data manipulation, statistical analysis, and machine learning.
Outcome:
The outcome of data analytics is to provide detailed insights and forecasts that can drive decision-making, optimize operations, and predict future trends and behaviors.
Implementation:
Data analytics implementation involves data cleaning, data transformation, exploratory data analysis, model building, and validation. It requires advanced statistical and programming skills.
Key Differences:
Scope and Purpose: BI focuses on providing a broad overview and historical insights through dashboards and reports, while data analytics delves into specific questions using advanced statistical methods.
Complexity and Depth: BI tools are designed for ease of use and accessibility, often featuring drag-and-drop interfaces, whereas data analytics requires more technical expertise in programming and statistical analysis.
Outcome and Usage: BI aims to support ongoing business monitoring and strategy through visualizations and dashboards, whereas data analytics provides deeper insights and predictions that can lead to more informed, data-driven decisions.
In summary, while BI provides the framework and tools for monitoring and understanding overall business performance, data analytics goes deeper into the data to uncover detailed insights and predictions.
Together, they enable organizations to harness the full potential of their data for comprehensive decision-making and strategic planning.
0 notes
Link
0 notes
Text
Hadoop and Spark: Pioneers of Big Data in the Data Science Realm
Introduction:
In the realm of data science, the sheer volume, velocity, and variety of data have given rise to the phenomenon known as big data. Managing and analysing vast datasets necessitates specialised tools and technologies. This article explores big data and delves into two prominent technologies, Hadoop and Spark, integral parts of any comprehensive data scientist course, that play pivotal roles in handling the complexities of big data analytics.
Understanding Big Data:
Big data refers to datasets that are too large and complex to be processed by traditional data management and analysis tools. The three Vs—Volume, velocity, and variety—characterise big data. Volume refers to the massive amount of data generated, Velocity denotes the speed at which data is generated and processed, and Variety encompasses the diverse sources and formats of data.
Specialised technologies are required to harness the potential insights from big data, and two of the most prominent ones are Hadoop and Spark, as extensively covered in a Data Science Course in Mumbai.
Hadoop: The Distributed Processing Powerhouse
Hadoop, an open-source framework, is synonymous with big data processing.
Created by the Apache Software Foundation, Hadoop facilitates the distribution of large data sets' storage and processing across clusters of standard hardware. It comprises two primary elements: the HDFS for data storage and the MapReduce programming model for efficient data processing.
1. Hadoop Distributed File System (HDFS):
At the core of Hadoop is its distributed file system, HDFS. HDFS breaks down vast datasets into smaller segments, usually 128 MB or 256 MB, and disperses these segments throughout various nodes in a cluster. This enables parallel processing, making it possible to analyse massive datasets concurrently, a key topic in any data science course.
2. MapReduce Programming Model:
Hadoop employs the MapReduce programming model for distributed data processing. MapReduce breaks down a computation into two phases—Map and Reduce. The Map phase processes and filters the input data, while the Reduce phase aggregates and summarises the results. This parallelised approach allows Hadoop to process vast amounts of data efficiently.
While Hadoop revolutionised big data processing, the evolution of technology led to the emergence of Apache Spark.
Spark: The High-Performance Data Processing Engine
Apache Spark, an open-source, fast, and general-purpose cluster-computing framework, addresses some of the limitations of Hadoop, providing quicker and more versatile extensive data processing capabilities.
1. In-Memory Processing:
One of Spark's key differentiators is its ability to perform in-memory processing, reducing the need to read and write to disk. Consequently, Spark outpaces Hadoop's MapReduce in terms of speed, particularly for repetitive algorithms and dynamic data analysis, due to its more efficient processing capabilities.
2. Versatility with Resilient Distributed Datasets (RDDs):
Spark brings forth the notion of Resilient Distributed Datasets (RDDs), a robust and fault-tolerant array of elements designed for parallel processing. RDDs can be cached in memory, enabling iterative computations and enhancing the overall speed and efficiency of data processing.
3. Advanced Analytics and Machine Learning Libraries:
Spark offers high-level APIs in Scala, Java, Python, and R, making it accessible to a broader audience. Additionally, Spark includes libraries for machine learning (MLlib) and graph processing (GraphX), expanding its utility beyond traditional batch processing.
Comparing Hadoop and Spark:
While both Hadoop and Spark are integral components of the extensive data ecosystem, they cater to different use cases and have distinct advantages.
Hadoop Advantages:
Well-suited for batch processing of large datasets.
Proven reliability in handling massive-scale distributed storage and processing.
Spark Advantages:
Significantly faster than Hadoop, especially for iterative algorithms and interactive data analysis.
Versatile with support for batch processing, interactive queries, streaming, and machine learning workloads.
Conclusion:
In the ever-expanding landscape of data science, big data technologies like Hadoop and Spark, critical components in a Data Science Course in Mumbai, are crucial in unlocking insights from vast and complex datasets. With its distributed file system and MapReduce paradigm, Hadoop laid the foundation for scalable data processing. Spark brought about advancements that address the evolving needs of the data-driven era. As part of a data science course, understanding these technologies equips data scientists and analysts with the capability to derive significant insights, thus fueling innovation and guiding decision-making across various sectors.
0 notes
Text
Unlocking the Power of Data Engineering
In the era of data-driven decision-making, businesses face the pressing need to efficiently manage and analyze vast amounts of data. This has led to the rise of data engineering, a field dedicated to transforming raw data into valuable insights. In this article, we will delve into the world of data engineering, exploring its key concepts, methodologies, and the impact it can have on organizations.
1. Understanding Data Engineering
Data engineering can be defined as the process of designing, building, and managing the infrastructure and systems that enable the collection, storage, processing, and analysis of data. It involves a combination of technical skills, domain knowledge, and creativity to bridge the gap between raw data and actionable insights.
2. The Role of Data Engineers
Data engineers play a crucial role in the data ecosystem. They are responsible for developing and maintaining data pipelines, which are the pathways through which data flows from various sources to storage and analysis platforms. Data engineers work closely with data scientists, analysts, and other stakeholders to ensure data quality, reliability, and accessibility. Enroll in Data Engineer Training Course to gain hands-on experience with cutting-edge tools and techniques, empowering you to excel in the dynamic world of data engineering.
3. Building Data Pipelines
Data pipelines are the backbone of any data engineering architecture. They enable the smooth and efficient movement of data from source systems to the desired destinations. Data engineers leverage various tools and technologies to build and manage these pipelines, including Extract, Transform, Load (ETL) processes, batch processing, streaming frameworks, and data integration platforms.
Refer this article: How much is the Data Engineer Course Fee in India?
4. Data Integration and Transformation
Data engineering involves integrating data from multiple sources, which may be structured or unstructured, into a unified format for analysis. This process often requires data transformation, where data engineers apply cleaning, filtering, aggregating, and enriching techniques to ensure data consistency and usability. Data engineers also address data quality issues, such as missing values, inconsistencies, and duplicates, to enhance the accuracy of downstream analyses. Join leading data engineer training institute to learn from experienced professionals and enhance your proficiency in handling big data and implementing scalable solutions.
5. Scalability and Performance
As data volumes continue to grow exponentially, data engineering must account for scalability and performance. Data engineers need to design systems that can handle large-scale data processing and storage efficiently. This may involve distributed computing frameworks like Apache Hadoop and Apache Spark, cloud-based storage solutions, and parallel processing techniques to optimize performance.
6. Data Governance and Security
Data engineering involves working with sensitive and valuable information. Therefore, ensuring data governance and security is paramount. Data engineers implement robust security measures, including data encryption, access controls, and data anonymization techniques, to protect sensitive data from unauthorized access or breaches. They also adhere to data privacy regulations, such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). Data Engineer Courses provides hands-on experience with industry-relevant tools and methodologies, equipping you with the skills to design and manage data infrastructure effectively.
Data Scientist vs Data Engineer vs ML Engineer vs MLOps Engineer
youtube
7. Data Warehousing and Storage
Efficient data storage and management are critical components of data engineering. Data engineers leverage data warehousing solutions, both on-premises and cloud-based, to organize and store data for easy access and retrieval. They design data schemas and models, implement data partitioning strategies, and optimize storage configurations to meet performance requirements and minimize storage costs.
8. Data Engineering and Machine Learning
Data engineering and machine learning go hand in hand. Data engineers collaborate with data scientists to develop data pipelines that support machine learning workflows. They preprocess and prepare data, perform feature engineering, and optimize data ingestion processes to enable accurate model training and prediction. Data engineers also play a vital role in deploying machine learning models into production systems. Discover the best data engineer course tailored to meet industry demands, empowering you with advanced data engineering knowledge and problem-solving abilities for data-driven success.
9. Data Engineering in the Cloud
Cloud computing has revolutionized data engineering by providing scalable and flexible infrastructure. Cloud-based data platforms, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure, offer a wide range of services and tools for data engineering tasks. Data engineers leverage cloud technologies to build cost-effective and scalable data pipelines, storage solutions, and analytics platforms.
XGBOOST in Python
youtube
Conclusion
Data engineering is a vital discipline that enables organizations to leverage the power of data. With the right data engineering practices, businesses can unlock actionable insights, make informed decisions, and gain a competitive edge in today's data-driven landscape. Earn a Data Engineer Certification to validate your expertise in data modeling, data integration, and data architecture, enhancing your credibility in the data engineering domain.
By understanding the key concepts, methodologies, and tools of data engineering, organizations can harness the full potential of their data assets and drive innovation and growth.
Reinforcement Learning in Python with Simple Example
youtube
0 notes